什么是后缀数组:
看几条定义(应该没啥用):
- 子串
在字符串$s$中,取任意$i<=j$,那么在$s$中截取从$i$到$j$的这一段就叫做$s$的一个子串
后缀
- 后缀
就是从字符串的某个位置i到字符串末尾的子串,我们定义以$s$的第$i$个字符为第一个元素的后缀为$suff(i)$
- 后缀数组
把$s$的每个后缀按照字典序排序,
后缀数组$sa[i]$就表示排名为i的后缀的起始位置的下标
而它的映射数组$rk[i]$就表示起始位置的下标为i的后缀的排名
即:$sa$表示排名为$i$的是啥,$rk$表示第$i$个的排名是啥
后缀数组的思想
先说最暴力的情况,对每个后缀排序$(nlogn)%,但是这是一个字符串,所以比较任意两个后缀的复杂度其实是%O(n)%,复杂度$O(n^2logn)$的,肯定会$T$,接下来需要把优化。
优化
优化1:倍增——对排序的优化
我们不是把每一个后缀字符串列举出来,当做没有联系的字符串进行排序,而是把每一个后缀都放在原串中考虑。
1.先根据单个字符排序,(即先按照每个后缀的第一个字符排序)。对于每个字符,我们按照字典序给一个排名(当然可以并列),这里称作关键字。
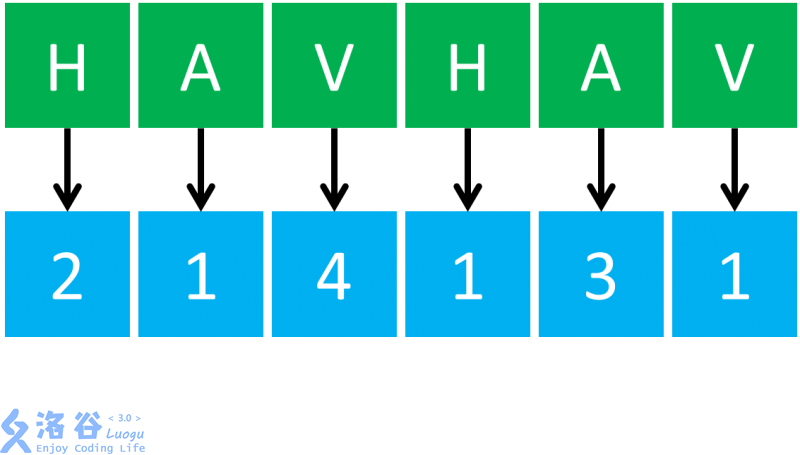
2.接下来我们再把相邻的两个关键字合并到一起(即先按照每个后缀的前两个字符排序)。这样就是以第一个字符(也就是自己本身)的排名为第一关键字,以第二个字符的排名为第二关键字,把组成的新数排完序之后再次标号。(没有第二关键字的补零)
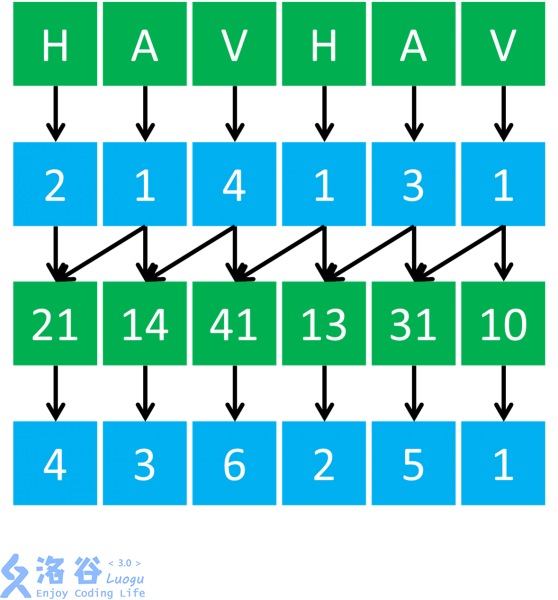
3.接下来就要倍增了:我们对于一个在第$i$位上的关键字,它的第二关键字就是第$i+2$位置上的,联想一下,因为现在第i位上的关键字是$suff(i)$的前两个字符的排名,第$i+2$位置上的关键字是$suff(i+2)$的前两个字符的排名,这两个一合并,不就是$suff(i)$的前四个字符的排名吗?方法同上,排序之后重新标号,没有第二关键字的补零。同理我们可以证明,下一次我们要合并的是第$i$位和第$i+4$位,以此类推即可
·
·
·
当所有的排名都不同的时候我们直接退出就可以了,因为已经排好了。
这样排序的速度稳定在$(logn)$
优化2——基数排序
如果我们用快排的话,复杂度就是$(nlog^2n)$ 还是太大。
这里我们用一波基数排序优化一下。在这里我们可以注意到,每一次排序都是排两位数,所以基数排序可以将它优化到$O(n)$级别,总复杂度就是$(nlogn)$。
介绍一下什么是基数排序,这里就拿两位数举例
我们要建两个桶,一个装个位,一个装十位,我们先把数加到个位桶里面,再加到十位桶里面,这样就能保证对于每个十位桶,桶内的顺序肯定是按个位升序的。
最长公共前缀——后缀数组的辅助工具
什么是LCP?
我们定义$LCP(i,j)$为$suff(sa[i])$与$suff(sa[j])$的最长公共前缀
为什么要求LCP?
后缀数组这个东西,不可能只让你排个序就完事了……大多数情况下我们都需要用到这个辅助工具LCP来做题的
关于LCP的几条性质
显而易见的
LCP(i,j)=LCP(j,i);
LCP(i,i)=len(sa[i])=n-sa[i]+1;对于$i>j$的情况,我们可以把它转化成$i<j$,对于$i==j$的情况,我们可以直接算长度,所以我们直接讨论$i<j$的情况就可以了。
我们每次依次比较字符肯定是不行的,单次复杂度为$O(n)$,太高了,所以我们要做一定的预处理才行。
几个性质
LCP(i,k)=min(LCP(i,j),LCP(j,k))
LCP(i,k)=min(LCP(j,j-1)) 对于任意1<i<=j<=k<=n
怎么求LCP?
我们设$height[i]$为$LCP(i,i-1)$,$1<i<=n$,显然$height[1]=0;$
由上面的几个性质可得,$LCP(i,k)=min(height[j]) i+1<=j<=k$
那么$height$怎么求,我们要利用这些后缀之间的联系
设$h[i]=height[rk[i]]$,同样的,$height[i]=h[sa[i]]$;
那么现在来证明最关键的一条定理:
$h[i]>=h[i-1]-1;$
首先我们设第$i-1$个字符串按排名来的前面的那个字符串是第k个字符串,注意$k$不一定是$i-2$,因为第$k$个字符串是按字典序排名来的$i-1$前面那个,并不是指在原字符串中位置在$i-1$前面的那个第$i-2$个字符串。
这时,依据$height[]$的定义,第k个字符串和第i-1个字符串的公共前缀自然是$height[rk[i-1]]$,现在先讨论一下第$k+1$个字符串和第$i$个字符串的关系。
第一种情况,第$k$个字符串和第$i-1$个字符串的首字符不同,那么第k+1个字符串的排名既可能在$i$的前面,也可能在i的后面,但没有关系,因为$height[rk[i-1]]$就是$0$了呀,那么无论$height[rk[i]]$是多少都会有$height[rk[i]]>=height[rk[i-1]]-1$,也就是$h[i]>=h[i-1]-1$。
第二种情况,第$k$个字符串和第$i-1$个字符串的首字符相同,那么由于第$k+1$个字符串就是第k个字符串去掉首字符得到的,第$i$个字符串也是第$i-1$个字符串去掉首字符得到的,那么显然第$k+1$个字符串要排在第$i$个字符串前面。同时,第$k$个字符串和第$i-1$个字符串的最长公共前缀是$height[rk[i-1]]$,
那么自然第k+1个字符串和第i个字符串的最长公共前缀就是$height[rk[i-1]]-1$。
到此为止,第二种情况的证明还没有完,我们可以试想一下,对于比第$i$个字符串的排名更靠前的那些字符串,谁和第i个字符串的相似度最高(这里说的相似度是指最长公共前缀的长度)?显然是排名紧邻第$i$个字符串的那个字符串了呀,即4sa[rank[i]-1]4。但是我们前面求得,有一个排在i前面的字符串$k+1$,$LCP(rk[i],rk[k+1])=height[rk[i-1]]-1;$
又因为$height[rk[i]]=LCP(i,i-1)>=LCP(i,k+1)$
所以$height[rk[i]]>=height[rk[i-1]]-1$,也即$h[i]>=h[i-1]-1$.
1 | #include<cstdio> |
<img src="https://img-blog.csdn.net/20151129213701642" width=256 height=256 />